发布时间 |
2024-03-10 |
4.28. 6.8
4.28.1. 大特性
4.28.1.1. Deadline Server
这个是解决实时任务独占的问题的。按RT类任务的系统承诺,这些东西只要在,就可以占光所有的CPU时间,这很容易把一些关键任务饿死。之前Linux的手段是设置一个门限,只让RT任务占95%的时间。但这样如果没有其他任务,剩下那5%的时间可能就是在Idle,有人又建议如果是Idle,就不要切换过去好了。但这也不好,因为有些几乎Idle,不那么重要的任务进去也不对。这个Deadline Server的方案似乎是创建一个特定优先级,Deadline Class的任务,用它来卡那5%的时间。
我最近在考虑未来穿插大量的AI运算的算力应该怎么调度,我把这些考量也放在这个上下文一起想一想。现在这些算法很多都用异构核(GPU,TPU,NPU等)来解决,最大的问题是有建立时间,一旦有建立时间,短时间的计算跨核调度又不值得,所以更好是作为协处理器放在本CPU内部。但放在本CPU内部利用率又不足。所以硬件无论如何都是做成CPU内部有轻量级的协处理器,重量级的拉到异构核上去算。这就给OS调度器造成压力了:首先是CPU必然是大小核的,因为不值得给每个CPU都配这些协处理器,然则调度器必须根据任务的计算特征选定不同的核进行调度,而且一旦遇到核不合适,就要触发异常,然后切换回具有这种计算特征的核上。这样的结果是什么呢?我认为是最终我们的CPU上会支持更多的线程,然后把这些协处理共享给多个线程共享使用,这样调度的工作就不是OS的了,而是硬件的。等线程足够多了,我觉得一定量的实时线程,就由它去吧,反正数量不要太多,占不光所有的CPU就行。这样一想,我觉得Linux解决的问题太多也不见得好。嵌入式或者安全性要求高的系统,就不要来参合Linux了。
4.28.1.2. Multi-Size透明大页
这个文档:Large folios for anonymous memory,定性folios的优势在于
让页的基础大小变得不那么重要。
对我来说,这个信息是最重要的。其他的算法问题,都是细节问题(很重要,但对不是写这个代码的人来说不重要),得个“知”字吧。
补丁的作者是ARM的Ryan Roberts。
4.28.1.3. Mount增加了两个系统调用
这个也是得个知字,我们就把接口列出来看一下就好了:
struct __mount_arg {
__u64 mnt_id;
__u64 request_mask;
};
int listmount(const struct __mount_arg *req, u64 *buf, size_t bufsize,
unsigned int flags);
struct statmnt {
__u32 size; /* Total size, including strings */
__u32 __spare1;
__u64 mask; /* What results were written */
__u32 sb_dev_major; /* Device ID */
__u32 sb_dev_minor;
__u64 sb_magic; /* ..._SUPER_MAGIC */
__u32 sb_flags; /* MS_{RDONLY,SYNCHRONOUS,DIRSYNC,LAZYTIME} */
__u32 fs_type; /* [str] Filesystem type */
__u64 mnt_id; /* Unique ID of mount */
__u64 mnt_parent_id; /* Unique ID of parent (for root == mnt_id) */
__u32 mnt_id_old; /* Reused IDs used in proc/.../mountinfo */
__u32 mnt_parent_id_old;
__u64 mnt_attr; /* MOUNT_ATTR_... */
__u64 mnt_propagation; /* MS_{SHARED,SLAVE,PRIVATE,UNBINDABLE} */
__u64 mnt_peer_group; /* ID of shared peer group */
__u64 mnt_master; /* Mount receives propagation from this ID */
__u64 propagate_from; /* Propagation from in current namespace */
__u32 mnt_root; /* [str] Root of mount relative to root of fs */
__u32 mnt_point; /* [str] Mountpoint relative to current root */
__u64 __spare2[50];
char str[]; /* Variable size part containing strings */
};
int statmount(const struct __mount_arg *req, struct statmnt *buf,
size_t bufsize, unsigned int flags);
两个调用是配合的,前者先查有哪些mount的,每个用一个id标识,然后再用id查每个mount的详细信息。
就是把原来从sysfs或者procfs的信息换到系统调用上,我觉得这个东西很适合我们的系统调用块方案,我希望多搞。
4.28.1.4. perf的Data-type profiling功能
很有趣的perf调试功能。用起来是这样的:
先用:
perf mem record ; 部分可以分开读写的平台可以加-t store参数
跟踪。然后这样看结果::
perf annotate --data-type=callchain_list
这样你会看到每个变量被访问的热点,像这样:
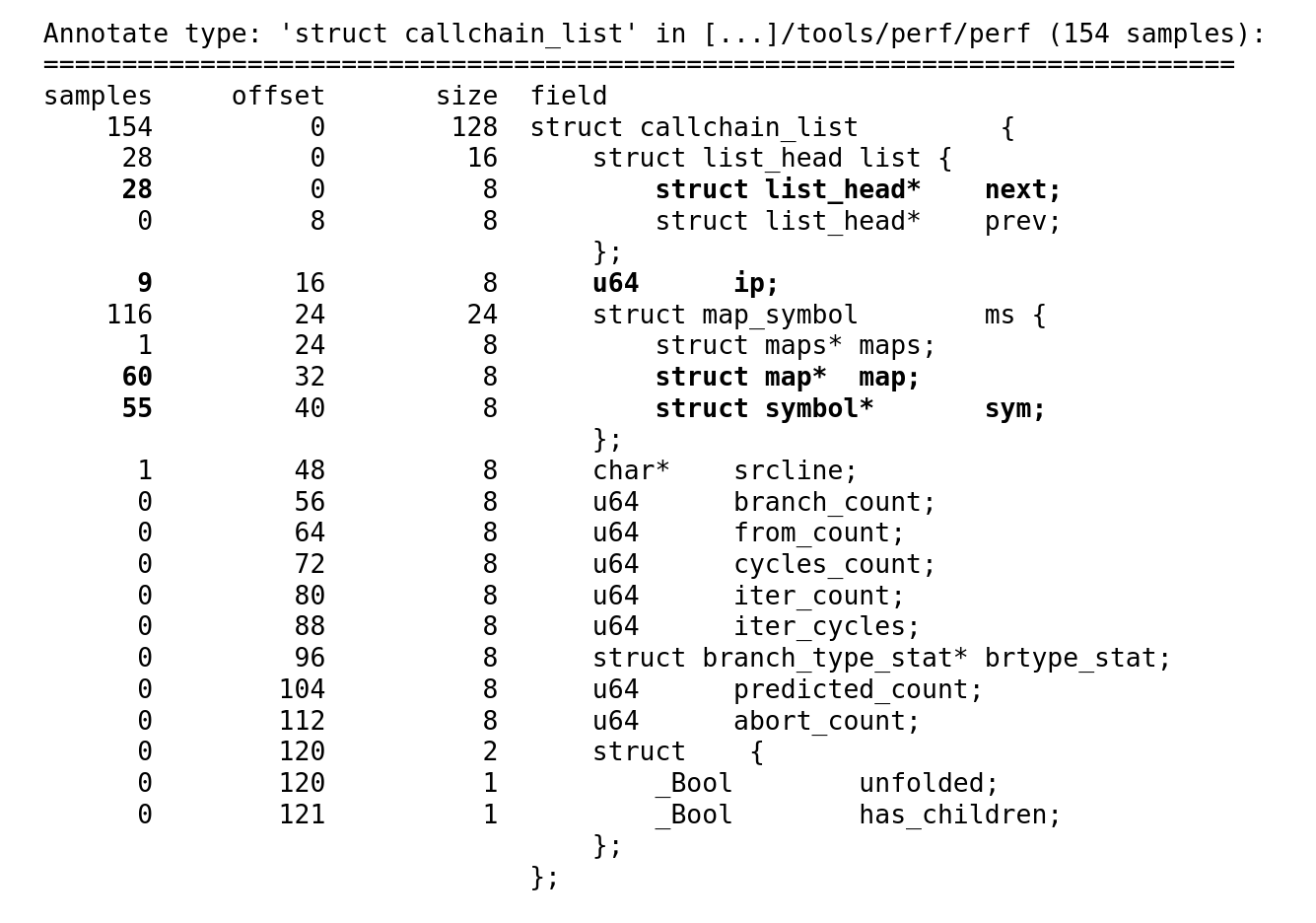
它的原理是在捕获到读写操作的时候,根据DWARF信息去获知具体是什么变量然后做的记录。
4.28.2. 其他有趣的东西
这个版本增加了一个配置能力:禁止裸写入已经mount的分区。但这是一个总结性的说法,修改是改在不同的文件系统的不同配置上的,只能说是在走这个方向。
LSM(安全子系统)增加了三个系统调用:lsm_list_modules(), lsm_get_self_attr(), lsm_set_self_attr()。我不搞这个子系统,不细看了。
增加了一个Intel \(X^e\)驱动,这是个独显,中文好像叫锐炫,有针对台式机和笔记本的不同版本。显存(DDR6)从4GB到16GB不等,主频900M到1.6G不等。但这里:Intel Core Ultra7显示我的Thinkpad Gen12上也集成了这个东西(有8个\(X^e\)核)。所以这个应该是个架构的品牌。而且,它的主频是2.25G,和集成的NPU的1.4GHz是不同的。这些厂家就是不把你的思路搞乱不罢休。
修改只涉及一个补丁,但涉及的文件很多,应该是内部开发后的第一个版本。
字节跳动提了一组用maple tree提升fork性能的补丁。
/proc/sysrq-trigger现在可以一次输入多个请求,但前面要加一个下划线,比如::
echo _tsu > /proc/sysrq-trigger
这相当于顺序写入t, s和u,没有下划线的话,就相当于只写了第一个。
龙芯在合入和rust/kvm有关的一些补丁。
海思鲲鹏修改了hccs和zip的驱动,都是小维护而已。