3.24. PCIE总线的保序模型
PCI 3.0规范(注意,这里说的是PCI LocalBus Specification,不是PCIE的标准,但后者基于前者设计)附录E描述的保序模型,跨越了软件和硬件两层设计的众多概念,很容易导致硬件设计者和软件设计者都对这里描述的模型在理解上产生误差,讨论不到一起去。本文帮助厘清这种偏差。
本文厘清这种误解的方法,是让所有的概念都回到软硬件接口的位置上,让无论是软件还是硬件的内部概念都映射回“软件访问地址空间”这个语言空间中。这种方式,也是作者提议软硬件在讨论接口的时候需要使用的方法:无论我们用什么办法描述自己在满足接口上的要求,我们都要把这种概念映射回“软件访问地址空间"这个模型中。
本文是为了和第三方讨论,不保证所总结的信息是正确的。
简单起见,本文忽略x86特有的io空间(通过in,out等指令形成的io地址空间),那个空间的行为可以通过一般内存load, store的地址访问行为作为类比来理解。
这样,CPU对设备和内存的理解可以抽象为如下模型:
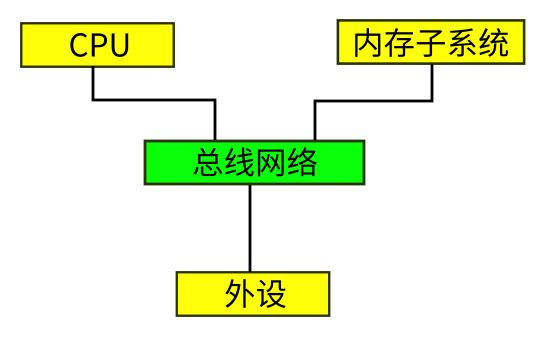
CPU通过对不同地址的读写,实现对内存或者外设空间的存取。一条读写指令的完成时间,取决于被读写的终点什么时候响应这个读写请求,如果终点响应慢了,或者这个终点不响应了,CPU的读写指令就会延迟,或者直接挂死。软件运行在CPU上,这就是软件可以看见的硬件行为的全部,无论你的总线系统有多少小九九,都必须反映到这个名称空间上。所有的行为,都应该反馈为读写的结果,以及这些读写行为的开始和结束时间。
对于这个名称空间,我们还有两个最基本的补充。第一,内存部分,我们称为“内存子系统”,而不称为“DDR”,表示我们认为Cache和DDRC,DDR都是一体的,只要CPU读写某个地址的时候能够拿到正确的值,我不关心你是从Cache中拿到的,还是直接从DDR中拿到的。
第二,CPU对读写指令一个重要的要求就是保序,每个CPU对内存或者IO访问的保序,只能保证到本CPU内部。比如读入一个地址,然后计算,CPU肯定会保证读入完成后,才进行计算。但它并不能保证它对内存或者IO空间的读写顺序,反映在其他CPU所观察到的情形上,和本CPU上看到的是一致的。CPU的内存屏障指令,可以让CPU可以等待这些指令行为,被传播到对应的观察者(其他CPU或者外设)上,但这种等待,是基于这些观察者的反馈,如果观察者没有给出正确的反馈,本CPU不会知道。
外设也可以操作内存(DMA),外设和内存子系统间有什么约定,那是外设和总线系统之间的事,CPU(软件)是不管的。外设只能把这种约定反映的顺序关系告知软件,从而形成CPU软件和外设软件(也可以认为是固件)之间的通讯关系,这种通讯关系,是建立在我们前面提到的内存访问关系之上的行为,而不被(软件工程师)认为是内存访问行为本身的一部分。
现在我们在来看看PCIE是怎么连接进来的:
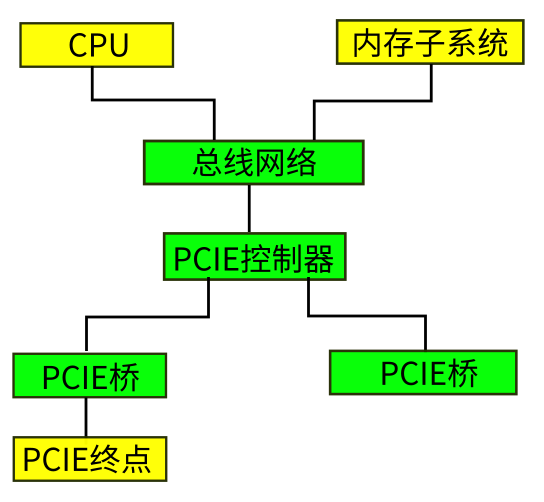
我们看到了,PCIE子系统其实是总线的延伸,但由于PCIE这个总线系统和CPU的总线系统来自不同的供应商(设计者),它们之间就必须有协议来优化和保证CPU(软件)的和终点(EP)之间的通讯。但这种保证,不能改变我们前面说过的那个名称空间。
也就是说,不管EP,PCIE总线和系统总线有多少交易, 这些交易都必须反映为CPU读写指令上的行为。
好了,我们现在开始看PCIE本身实现上的难处。PCIE总线是个多层总线,很多时候,它的速度比系统总线慢得多(时延或者带宽上都有可能慢)。为了提高速度,它用了两个优化:
第一,写操作(Posted),可以由网桥直接响应完成。也就是说,CPU发下去的一个IO写,在发到EP前,就可以结束(由PCIE的中间网桥响应结束)。(注:这个结论本身是错的,只是说原理如此,帮助理解,理由下文解释)比如你执行::
*((volatile u32 *)0x12345678)=0x01;
向EP的特定地址写1(假定这是命令EP“开始执行”),这条指令返回(结束)了,其实EP并没有执行,如果你随后发出另一个依赖这个“执行”的指令,后一个依赖的指令就可能失败。这个设计带来的好处是,如果多个写操作之间没有依赖关系,你连续执行写操作,就有机会让效率提高。
这种优化无法发生在读操作上,因为“读完成”需要提供读到的数据,所以请求没有发到EP上,你无法返回。
第二,鼓励使用内存(CPU访问内存或者EP做DMA)取代IO访问进行通讯。如前所述,PCIE写操作(Posted)是可以不用等待的,但读操作通常都需要做等待(这样会导致做完一个通讯来回,再做下一个,严重拖慢带宽),所以,读IO空间会非常慢,更好的方法是,直接让EP通过DMA写入内存,CPU从内存读数据。从而不会拖慢CPU的执行效率。一种常见的做法是,比如我要做一个网卡收报的功能,网卡(EP)直接向内存中写数据,等待写够了,最后用MSI消息(MSI消息也是一个从EP发起的写操作,只是对CPU的效果是产生中断)通知CPU(驱动):“数据已经准备完成了,请从内存中获得数据”。
我要提醒的是,你EP和PCIE子系统可以知道你发出的是每个读写请求是有顺序要求的(Strong Ordering),还是没有顺序要求的(Relaxed Ordering),但CPU(软件)是不会知道的。所以你不能给软件引入RO,SO这些概念(不是说不能提,而是你谈接口的时候不能依赖这个),你只能告知软件,数据有效的时机是什么(某个flags被置位,或者收到特定中断以后)。
PCI 3.0标准附录E把这个软件的需求和硬件的行为放到一起了,对我来说,它的描述还是很清楚的。但它不是软件编程指引,甚至我会认为它对软件编程没有任何指导价值,你必须基于这个协议,给软件设计师提供EP和CPU对应驱动的通讯协议。
附录E能给软件提供的信息是:
内存之外的所有读写操作,都不是Posted操作。也就是说,软件对IO空间的所有读写行为,从发送到总线一刻起,就是保序和缓慢的(必须由EP响应)。所以,快速通道是CPU和EP通过内存进行通讯,但两者(在内存上)的保序关系,只有EP才有决定权(基于Ordering Rules for a Bridge),CPU一侧完全不能控制(通过配置EP或者PCIE控制器来改变是另一个回事)
2.多个CPU在IO空间访问上确定的顺序,不能被按顺序传递到EP上。软件不能依赖这一点设计协议。换句话说,同步必须由EP完成,不能依靠CPU间的同步来实现对EP的控制(因为Retry的存在)
PCIE协议没有保证“对EP的读写操作会保证,CPU Cache中的数据被EP感知”,CPU必须主动保证对EP的IO请求前,完成Cache的Flush。
注:页表本身的属性,内存访问本身是否带#LOCK标记,可以在一定程度上影响CPU对PCIE总线发起的Transaction的行为,但由于这不影响我们的结论,这里一概忽略。