..KennethLee版权所有2018-2020
:Authors:KennethLee :Version:1.0
3.103. YVR18资料关注点
3.103.1. PAC和BTI特性的目的
今年由于计划冲突没有参加LinaroConnect,假期把会议分享的材料都看了一遍,把有意思的一些信息总结在这里。
资源在这里:YVR18Resources,部分是演讲视频,部分包括胶片,但也有很多是两者都没有的,按我的经验,会议结束后还没有的,后面也补不回来,所以,基本上你这里能看到的就是所有的材料了。
材料都有编号,格式是Nnn,其中N是第几天的会议,nn是序号,后面提到相关材料的时候,用序号来表示。
(注:由于我和这个组织有利益相关,所以这里只从个人角度谈个人觉得有趣的技术,不做评价,也和Linaro的运作策略无关。)
ARM在指令版本v8.3(这里都是指A系列)的时候开始引入PAC,到v8.5的时候引入了BTI。分别是对数据和指令访问进行了更复杂的控制。我只深入看过PAC的Spec,大概的意思是可以给页面(在PTE上)加上一个tag,然后当你访问这个地址的时候,如果所使用的指针(64位系统的指针有一部分空间没有用)没有带有这个tag,就异常。
而BTI的作用从介绍上看是类似的,不过是作用于代码,如果你跳转到另一个地址,而你所执行的指令的页面上给定一个标记c,跳转的目标指令如果不以btic开头,就异常。示例代码如下::
start:
blrx0
...
good: //如果x0定位在这里,就是正常的
btic
...
bad://如果x0定位在这里,就会异常
movx0,#16
...
我最早看PAC的Spec的时候,第一反应是这东西是用来支持pkey_mprotect()的(要知道这是什么,请参考manmprotect,它是mprotect的升级版本)。但从这次会议的介绍来看,这两个特性首先考量的目标场景是保护ROP和JOP。
所谓ROP和JOP分别是ReturnOrientedProgramming和JumpOrientedProgramming,这是两种攻击技术。我们平时用得最多的缓冲区攻击都是找到那些对入口参数判断不严谨的函数,然后通过非法的输入参数,诱导这些函数越界访问堆栈中的数据,冲掉函数的返回值,从而让程序执行到另一个地方,实现攻击(比如更改攻击程序的权限,在root权限代码中创建一个Shell等),这就是ROP。而JOP是一种更广泛意义的ROP,由于很多程序(特别是C++一类的面向对象程序),经常使用跳转表,如果越界访问可以攻击到跳转表,同样可以控制整个执行流程。
我猜这两个特性最终都会依赖pkey_mprotect()来实现的,但理解这两个特性的最终目的,也许能让我们更加清楚应该如何测试这两个特性是否发挥了作用。ARM在介绍中说使用PAC和BTI后,可以大幅降低制造ROP和JOP的Gadget代码的代码量,这个地方是我没有看懂的,也许当时会场上有特别的解释?否则难道是把ROP和JOP当做是编程语言设计方法了?但无论如何,PAC和BTI都是保护的方法。所以,我猜这也许是节省了保护代码的代码量吧,以后有机会再确认这个问题。
老实说,现在ASLR,KPTI,pkey_mprotech这些技术盛行,以后调试会变得越来越困难。而且,从架构的角度说,安全设计一定会让系统级调试会变得非常复杂,这次演讲102中提到的RAS的报告流程,从硬件报到安全EL3,然后进非安全UEFI,然后又到安全EL0,准备完数据又进非安全EL2和EL1,最后回到EL0的rasdaemon,这个在真实硬件上麻烦得一逼。
所以,我有个感觉,未来的调试会越来越聚焦到虚拟机这一层。演讲118提到qemu的TCG调试功能(这个功能不叫这个名字,只是是在这个特性中做的)就是一种很好的体现。我大概提炼一下这个功能是怎么用的[注1]:
qemuTCG功能可以用于qemu-user和qemu-system,我个人很少用user,我用system为例。当你启动qemu后,可以通过^ac切换到qemu的虚拟机控制台,然后你可以用如下命令来查你可以跟踪的事件::
infotrace-events
这个命令可以带参数对结果进行过滤::
infotrace-eventsgicv3_*
确定你要跟踪的事件后,用trace-event来跟踪对应事件,用trace-file设置跟踪文件(也可以直接通过命令行参数-trace指定)::
trace-eventsgicv3_*on
trace-filesetmytrace.out
qemu不是时钟精确的模拟器,暂时来说我还找不到非要用这个东西调试的场景,不过我对这个东西的未来还是抱很高的期望。
注1:很多平台的qemu都没有开启trace功能,可以考虑自己编译一个,使用如下configure选项::
--enable-trace-backends=ftrace|log|dtrace|syslog
推荐选择log,这个比较容易实验。我简单试用了一下相关功能,Bug不少,功能的自洽性也比较差,暂时离实用还有距离。有人可能觉得这个东西用Foundation或者FPGAEmulator就可以代替了,但这两个东西的效率和价钱……对吧?
3.103.2. HPC相关进展
Linaro的HPC实验室筹划了有相当长的时间了,这次第一次看到有实物介绍出来(116)。网络上包含两个1G的子网,用于外部接入(uplink)和BMC访问(bmc),以及两个100G子网,用于Lustre文件系统(fs)和InfiniBand(mpi)。
软件栈使用CentOS(未来可以扩展到OpenSuse),Warewulf(集群管理)和Slurm(Workload管理)。
投入的客户硬件包括华为和高通的服务器,InfiniBand都使用Mellanox的ConnectX上的板卡(而不是SoC上自带的RoCE功能),软件使用OFED。
文件系统使用Lustre,据说过程比较痛苦,因为Mellanox的部分驱动不是开源的,每个有这种商业公司介入的领域,都只能一个个单独合作,不太适合作为合作的中心。RoCE如此,GPU也是如此。OPTEE其实也是一样的,给我的感觉,这个东西用于实用,不如说定义了一个非安全软件(比如Linux)和安全软件之间进行通讯的接口定义。
203介绍了一下LLVM的进展,聚焦在指令调度上,不做编译器的估计不会太关心。
todo:其他的待补
3.103.3. Treble
Treble方案在Linaro推了3年,从一开始谁都说不清楚是什么,现在再看,看起来比较成熟了,虽然我自己不做手机方案了,但现在有人想到要“在服务器领域也可以学习Treble的优秀实践”,所以我也来总结一下Treble方案的核心在什么地方。
Treble现在比较完整的叙述在这里:
https://source.android.com/devices/architecture/
https://source.android.com/devices/architecture/images/VNDK.pdf
它的目标现在也比较清楚了,是要把Framework部分完全独立出来,让升级Framework不需要跟着下面Vendor相关的部分相对独立。
Treble提供了类似以前CTS兼容性测试套件类似的VTS前向兼容测试套件对兼容性进行测试。
Treble兼容性通过升级的HAL层实现,为此引入了一种HIDL语言来描述两者之间的关系,定义了两种HAL:
1.绑定式:主要用于流量不大的接口,基于Binder进行通讯
2.直通式:主要用于流量大的接口,基于传统的调用进行通讯,有可能是在同一个进程内(SP-HAL),也可以通过共享内存来实现(比如传统的HWComposer)
HIDL本质上是对Binder接口的封装,源文件用hal做扩展名,很类似过去Binder的Java接口定义文件,像这样::
interfaceIBarextendsIFoo{//IFooisanotherinterface
//embeddedtypes
structMyStruct{/*...*/};
//interfacemethods
create(int32_tid)generates(MyStructs);
close();
};
如果是绑定式或者共享内存式,Framework和HAL间就是IPC调用,如果是SP-HAL方式,就变成dlopen,然后直接进行相关的本地调用。
拿个现场的图来看更简单:
..figure::treble.jpg
在内核上,Treble推出了一个公共的主线:https://android.googlesource.com/kernel/common/,但从介绍材料上看是推荐性质的,还没有能力让各家都使用同一个内核,这应该是一个合作效率的问题。Google在Linaro上的项目是要拉着几个主要的供应商一起维护这个内核,但以AOSP现在的升级速度,我觉得真正实现这个会比较困难。
..figure::treble2.jpg
Treble要求各家必须使用ko的方式提供驱动,然后尝试把通用内核和驱动放在vboot分区上,Soc相关驱动放SoC分区上,ODM的相关驱动放在ODM分区上。希望可以独立升级通用内核部分,我个人不是很看好这种模式。我认为他们升不了几个版本的。
从星期五的KeyNotes上看到,Google对于统一内核的主要考量是质量,他们认为没有持续维护,代码的安全令人担心。但他们也承认这个问题在于,SoC的生命周期太短,这是影响厂商投入到代码主线化的动力。AndroidCommon版本的质量保证用例主要来自两方面:LTP和VTS(VendorTestSuit,通过sysfs激活Android相关功能)。
我个人不太认可这种实践可以用于服务器的。所谓接口稳定,前提就是接口没有改进需求了。是改进期望影响了接口的稳定性,而不是接口稳定性的需求决定了如何改进。在PC领域,很早就实现前向兼容了,而在几乎一样软件栈的服务器领域,到现在都没有完全实现前向兼容。是因为在现在这个阶段,服务器还在拼性能,所以很多东西都还在修改,这种情况下主动去把接口稳定下来,这是自己找死。
Treble花了三年成了现在的样子,有一个很重要的要素是这两年AOSP已经玩不出什么花样了,你一个接口随你玩一两年都是一个样子,收缩起来是有意义的,但如果你不是,那就是自己束缚自己了。
对了,演讲207中提到Treble把SELinux作为基础的安全保护错误,避免system和vendor的代码可以访问其他分区。这个有空到是可以看看具体是怎么设计的。
3.103.4. SPDX
最近上传LinuxKernel的代码的时候,都是拷贝别人的版权声明头,比如这样::
SPDX-License-Identifier:GPL-2.0+
一直没有认真去看看为什么现在都这样写声明了。209演讲里面,LinuxFoundation有人来讲了相关的背景,这都源自这个项目:SoftwarePackageDataExchange(SPDX)
它定义了被广泛使用的常见版权的“标识”,建议通过这些标识来唯一定义一个版权声明。所以现在Linux内核中都统一使用上面那样的声明方式。
实际上,根据最新定义的2.0版本,上面那个定义应该写成::
SPDX-License-Identifier:GPL-2.0-or-later
GPL-2.0+已经被废弃了。
源代码中包含这样的声明,编译工具有就有机会找到对应的声明,生成内置在二进制中的版权声明段,或者直接在输出中包含一个版权声明文件。
所以,以后写开源代码,不妨查一些这个列表:SoftwarePackageDataExchange(SPDX)spdx.org
然后直接在源文件的最前面加上这个声明。更详细的表述方法,可以参考演讲221中的L4Re的声明方法:kernkonzept/l4re-core
3.103.5. 当前的Linux调度器设计
演讲220对Linux当前的调度器做了一个科普,感觉不深不浅的,不知道对大部分读者是否具有参考价值。我对来说,已经很久没有看Linux的调度器了,很多原来没有很明确的概念,经过这些年的发展,现在变得非常清晰,所以参考价值还是挺大的。我就着这个演讲描述的概念,以及我自己掌握的一些东西,为这里的读者普及一些Linux调度器的初步知识,也算是我自己对这部分信息的一个总结吧。
我们先来理解一下调度器面对的问题。我不知道没有写过调度器的读者是否会和我一样,在我自己做操作系统设计之前,比如在学校学习操作系统原理的时候,我对调度器的认识,有一个很大的误区,似乎调度器是“决定把哪个进程投入运行”的一个算法,但实际上,它是“决定把哪个要运行的进程投入运行”的一个算法。这句话听起来一样,其实是不一样的,后者意味着,在每个调度“时刻”,你只需要管要运行的进程,不用管其他进程。我们很容易从一个时间广度上考虑这个问题,觉得调度器需要考虑所有的进程的状态,实际上调度器只考虑现在就可以运行的进程的状态,算法只需要考虑在调度序列中的进程,其他进程,都是不管的。这个现在单独跟你说,你会觉得“这谁不知道啊”,但等你看算法的时候,你可能就晕菜了。我们先把这个前提放在这里,以便读者后面更容易理解概念。
其实也正因为这个理解不同,我们更多人能接受“CPU占用率”这个概念,而不是Load这个概念,CPU占用率是时间广度的,是人的概念,而Load是一个时刻深度的,是调度器的概念。人关心的是某段时间内,CPU的利用率有多高,一个时刻是没有CPU占用率这个概念的。而调度器关心的是现在还有多少了进程等着被我调度,我让谁先上来,所以,这些被等着调度的进程,就是我的Load。
理解CPU占用率和Load的分别,我们就会发现,调度器其实比我们想象中简单,因为调度器是不考虑你的历史的,调度器考虑的是你这个进程加入到我的调度中后,我把你排在第几位执行,如果你休眠了,你的历史就被清除了,我才不在乎你过去用了多少CPU呢(其实不完全是这样,但我们先这样理解)。
有了这些基础,我们现在来理解一下调度器面对的问题。首先,我们有一些任务是很重要的,如果它要运行,就必须让它先运行。这我们称为实时任务。实时任务是最容易处理的。我刚入行的时候,一位做UnixOS的前辈就跟我说,RT调度器那就是玩具,基本上就让它先执行就好了。同是RT进程的话,也只有RoundRobin和FIFO两种算法,如何工作你猜都能猜到,最多就是补充一些优先级反转之类的保护,基本上没有什么值得发展的。这部分的算法,本文也会忽略。
难的是普通的任务怎么调度。一个简单的思路,根据任务的优先级(nice),每个任务给定一个调度时间片,然后每个任务用完自己的时间片,就等着,等到所有的任务都用完自己的时间片了,就重新开始。
但你真的按这样的方法来试试,你就会发现,你这个系统基本上不可用。为什么呢?因为任务有两种,一种是iobound,一种是cpubound的。iobound的任务处理io,cpubound的是长时间执行,只是在消耗CPU。如果你平等地对待他们,每个任务执行50ms,10个cpu bound的任务,1个shell,然后你在shell上按下一个a,这个a要等500ms才能回显出来,这玩意儿没法用。要保证iobound的进程在前面,否则这东西没法用。这是大部分普通调度器要解决的问题。
Linux在O(1)之前的调度器基本上是个玩具,那个东西我们就忽略了。我们先看O(1)调度器的原理。从名字就能看出来,O(1)算法是要保证取下一个运行任务的时候,算法复杂度是O(1),它用这样的数据结构:
..figure::o1调度.jpg
待运行的任务都挂在Active队列下面,每个Active分优先级Hash开,在用一个bitmap标记哪个队列中有任务,这样,要投入运行,只要检查一下bitmap,然后拿那个队列的第一个任务运行就可以了(这就是这个算法称为O(1)的原因)。当一个任务的时间片用完了,就改挂到Expired队列。等Active队列空了,就把两者换过来,问题就递归了。
这个算法最大的破绽你也看到了,它区分不了谁是iobound进程。所以O(1)算法有一个非常不好看的补充算法,主要是根据每个任务是否能用完自己的时间片就离开调度队列,如果是这样,调度器就“补偿”它,提高它的Effective优先级,这样,它回来的时候,就可以比较早得到调度了。我以前玩得比较多的就是这个算法,这个东西经常错判,而且很难调试。后来,它就逐步被CFS取代了。
CFS在2.6.23开始引入内核,在2.6.30彻底取代了O(1)算法。它引入的变化首先是用sched_class把不同的调度算法彻底分开了。正如演讲220中提到的,现在调度分了两层,先按调度类别分类,优先调度高优先级类别的任务。这样,我们做普通调度的时候,就不再需要考虑比如实时任务这样的任务了。
比如现在的内核中就包含了这些类别:
STOP:系统任务,比如RCU,ftrace,核间迁移。这些任务凌驾于所有其他任务有限调度
DL:DeadLine任务,这些任务有“必须什么时候完成”这样的诉求,所以在所有客户任务中优先调度
RT:就是过去的实时任务了
CFS:这才是普通的任务调度
IDLE:这是IDLE任务swapper/N
这一层的原理非常直白了。
然后,我们仍单独理解CFS。完全公平调度。首先我们理解一下什么是“完美的公平调度”,比如说,你有4个任务a,b,c,d,分别要运行4,4,8,12毫秒,CPU的时间片单位是4ms。
那么前四个4ms,应该是a,b,c,d每个周期各运行1ms,第五、六个4ms,a,b不在了,c,d应该每个周期各运行2ms,这样,c也运行完了,剩下的d,再运行第七个4ms,把4ms全部用完。这样就是完美的完全公平。
但我们做不到,因为我们不能无时无刻去比这些时间。所以,CFS就是一种“尽量公平调度的方法”,每次到了一个调度点(比如时钟中断),它马上算一下现在的任务花了多少时间,把这个时间加到它的vruntime中,之后调度的时候,总是取一个vruntime最短的任务来执行。
这样,天然地,运行得最少,经常休眠的任务的优先级就会变高,总是优先得到调度了。
这个算法纯从计算上逼近iobound进程优先执行。比O(1)算法可控多了。
但它的破绽也是很明显的,如果你要装你是个iobound进程,你只要避开vruntime的计算点,每次休眠一点点时间,就能保持你的优先级。
所以,实际上CFS还有很多补充算法来解决很多具体的问题,但无论如何,这个模型还是比O(1)可控。
其实吧,也没有保证能公平的调度算法,这最后基本上就是调整出来的。也许等待AI的影响力足够强,这东西应该是通过神经网络自动训练出来的?
3.103.6. 内核测试手段
演讲224和301介绍了在kselftest中增加ftracetest用例,还介绍了在内核中做GCOV的方法。这让我想起要把Documents/dev-tools目录看一遍,就着写这个总结,我把相关的逻辑理一下。
Linux内核进展越来越快,越来越成熟。现在上传一个特性到内核中要经过的测试越来越多了。过去我们一般会做checkpatch,内部review,然后进行功能,LTP测试,就可以开始上传了。
几年不看,其实现在已经不止有这些方法了,我们分两个维度来看:
静态检查的,除了checkpatch,我们还可以用sparse。用法如下(在安装了sparse的前提下)::
makeC=1
这会增加更严格的惯例检查。检查是附属在普通编译过程中的,如果你已经编译了所有.o了,这个检查不会发生。
还有一个更强大的是胭脂虫(coccinelle),用法如下(在安装了coccinelle以后,注1):
makecoccicheck
这个命令可以缩小到某个目录的范围内,比如::
makecoccicheckM=my/own/directory
我试了一下,这个检查的功能还是很强大的,比如我的代码中有这么一行::
q->svas->nr_pages=(vma->vm_end-vma->vm_start)>>PAGE_SHIFT
它还能报这种错::
WARNING:Considerusingvma_pageshelperonvma
这个可以作为上传前标准检查的一部分。
动态检查的,我们有如下工具可以用:
3.103.6.1. kselftest
这个类似LTP,是内置的一组功能测试用例,这样编译和运行::
make-Ctools/testing/selftest
makekselftest
其实编译出来的就是一个个独立的可执行程序,拷贝过去直接运行就可以了。
三星开源group在星期四的Keynote里介绍了这个东西的测试策略,要了解细节的可以听一下。我看了一下代码,这个基本上是个很自由的测试用例,框架本身仅仅是提供错误计数一类的东西,其他是你爱怎么写就怎么写。
3.103.6.2. gcov
这是把gcov的功能用到内核上。在用户态做单元测试一般会用gcov和lcov检查覆盖率的,这个功能现在在内核中也可以用了。它通过配置项CONFIG_GCOV_KERNEL使能。开启后,可以在/sys/kernel/debugfs/gcov找到所有跟踪数据文件(.gcda),用gcov命令就可以直接看到代码的执行覆盖率。
3.103.6.3. kmemleak和Kasan
这两个是自动内存检查,前者发现内存泄漏,后者发现use-after-free错误,分别通过CONFIG_DEBUG_KMEMLEAK和CONFIG_KASAN使能,发现有问题会自动抱错的,可以作为基本CI系统的一部分来用。
还有一个Kcov,我在ARM64平台跑不起来,就不讨论了。
注1:我自己使用Ubuntu18.04,这上面的coccinelle版本很旧,在最新的内核(4.19)上运行不起来,建议下源代码自行编译。另外注意:coccinelle的configure写得有问题,检查不到部分开发库不存在的问题,所以如果编译失败,根据名称安装对应的开发库即可。
3.103.7. AutoFDO@ARM
演讲416做了一个关于在ARM平台上使用perf的介绍,除了有一些基本的如何使用perf的知识以外,特别介绍了使用基于perf使用CoreSight(注1)等ARM专有功能。
但我比较感兴趣的是里面关于AutoFDO的例子。
所谓FDO,是gcc等编译器的一个特性,Feedback-DirectedOptimization(link)。编译程序有一个很难处理的问题是如何判断代码的分支是跳转还是不跳转(这东西影响流水线),芯片OoO(Out-of-Order,预测执行)设计很大程度上也是为了解决这个问题。FDO的方法是编译器先编译一个Instrumented版本(加通过gcov技术),运行一次,收集到所有的跳转数据了(在.gcda文件中),用这个数据来判断跳转的可能性是怎么样的,然后再用这个数据生成一个优化过的版本,正式使用。
下面是我在我的桌面机器上用这个技术运行gcc的例子的结果。编译过程如下::
BN=bubble
ALL=$(BN)_o0$(BN)_o3$(BN)_fdo
all:$(ALL)
$(BN)_o0:$(BN).c
gcc$<-o$@
$(BN)_o3:$(BN).c
gcc-O3$<-o$@
$(BN)_inst:$(BN).c
gcc-fprofile-generate$<-o$@
$(BN).gcda:$(BN)_inst
./$(BN)_inst
$(BN)_fdo:$(BN).c$(BN).gcda
gcc-O3-fprofile-use=$(BN).gcda$<-o$@
test:$(ALL)
./$(BN)_o0
./$(BN)_o3
./$(BN)_fdo
clean:
rm-f$(ALL)$(BN)_inst*.gcda*.gcno
.PHONY:testclean
结果如下::
./bubble_o0
Bubblesortingarrayof30000elements
3060ms
./bubble_o3
Bubblesortingarrayof30000elements
1477ms
./bubble_fdo
Bubblesortingarrayof30000elements
1161ms
对于这种算法类的程序(段),还是很有效果的。
FDO的最大缺点是代价很高,你没法拿一个-fprofile的版本直接到工作环境里面去用。但perf是没有这个问题的。所以,gcc还推出一个特性,叫AutoFDO(应该是Google提出来的,这个东西特别适合数据中心),它是用perf数据生成需要的.gcda文件,这样我们很容易在工作环境中拿到对应的数据了。
AutoFDO依赖于PMU的这个特性:PERF_SAMPLE_BRANCH_STACK。简单说,就是branch事件要分taken和untaken独立记录。现在很多ARMSoC不支持这个特性。演讲416提出的解决方案是用CoreSight来解决这个问题。
我要想要的解决方案不是这样的,我想要的解决方案是推动所有服务器SoC供应商把这个作为标准特性来提供。
注1:CoreSight是一个硬件跟踪器,自带内存,内置在SoC中(很多ARMSoC实现中都有),它可以直接从硬件的角度跟踪事件,我感觉对芯片设计师的作用大于软件设计师。用法和不同的perfrecord/report的模式基本上是一样的。
3.103.8. 其他
最后补充一些零碎的关注点:
- https://lkft.linaro.org/,ARM世界的功能测试,进展太慢了,到现在连块服务器单
板都没有104中ARM总结了一下Aarch8的特性引入时间,感觉挺有助于记忆的,我贴上来:
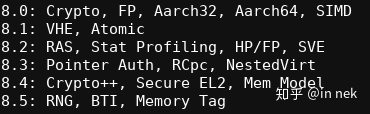
Home - Akraino Edge Stack,ARM热推的“雾计算”的一个实现,我觉得是一个卖轻量级服务器的市场
212中介绍TI在switchdev上的进展,我看到有趣的地方是,有可能以后我们就不要做网卡了,直接做个交换机进去,host端的网卡都是虚拟出来的,连着一个内置的交换机,物理端口是对外连的,这样对内部网络的加速就很容易做了
221:kernkonzept/l4re-core,L4Re来做了一个介绍,这个东西和libOS是两条路,libOS是Linux做主管理,虚拟机跑嵌入式。L4Re是Hypervisor做主管理,Linux做子功能。还在车载系统上用什么的同学可以考虑看看
223:简单入门了一把怎么用slang写工具,这个我其实特有兴趣,因为理论上编译器已经做了词法和语法分析,如果我要用其中的信息,应该可以在这个基础上加一点点代码就可以了。不过我看了一把,就没有什么兴趣了,虽然它确实符合我的要求。但这个“加一点点代码”还是很费脑子的,不是专门搞这一块的,耗不起这时间。不过偶尔用clang -Xclang -ast-dump -c test.c加上python简单处理一些东西还是可以的。
404提到未来devtree的一个发展方向,要加上一个语法定义文件了,过去devtree的自由度太高,定义了无效的,对不上的变量,要运行才能发现。这个方案提供了一个yaml定义问题,在编译内核的时候用make dt_binding_check检查所有的dts文件描述是否有问题。这个设计其实如果结合coccinelle等发展方向来考虑,就会发现,其实下一代语言的发展方向可以逐步会走向DSL,形式验证等技术估计也得像这个方向走才有出路。而发明新的编程语言和操作系统,反而感觉是重建匹配曲线,成功的机会更加渺茫
405提到了OpenJDK11的发布(半年一个版本,3月发布了10,9月发布11,没毛病),其中谈到一个重要的特性是GC的优化,在ARM上使用了TBI技术(Top Byte Ignore,就是64位指针的最高字节反正用不上,用来放其他信息),占用其中四位来表示内存的状态(remapped, fnalized, 2xMarked),这一看就省了不少GC的指针数据结构,希望可以看到性能的提升。
主要就是这些了,这个系列到此为止。